
Internet Archive : une ressource à disposition de tous les internautes
Le site Actualitté a rappelé récemment le rôle important joué par Internet Archive dans la conservation de la mémoire du web et comment chacun pouvait contribuer à cette oeuvre collective d’archivage de pages web. Un simple clic dans son navigateur permet la conservation à long terme de la page qu’on consulte. A partir de la même extension pour navigateur, on peut aussi retrouver une page retirée d’un serveur sous réserve que celle-ci ait bien été archivée. L’archivage des sources fait aussi partie de l’attirail des journalistes pour conserver des traces que certains acteurs auraient tendance à vouloir supprimer après coup comme des menaces ou des contenus haineux envoyés sur les réseaux sociaux mais aussi -même si tout le monde a le droit de changer d’avis, la base de l’honnêteté est de reconnaître ces changements- des déclarations antérieures d’hommes ou de femmes politiques qui s’avèreraient contradictoires avec des déclarations ou des décisions récentes, etc. Lorsqu’un responsable politique affirme avec aplomb l’inverse de ce qu’il soutenait quelques mois plus tôt, son équipe de communication n’a besoin que de quelques heures pour supprimer les contenus gênants sur le site officiel, mais les utilisateurs d’Internet Archive sont souvent plus rapides encore pour garder la trace de ces revirements (quand cela n’est pas pris en charge par une collecte automatique).
Lorsqu’on fait de la recherche en open source, Internet Archive est aussi le lieu où l’on archive ses preuves. C’est ainsi par exemple qu’Internet Archive a pu copier et conserver le message démontrant la responsabilité d’une milice du Donbass dans le crash du vol Malaysian Airlines MH17
Liens cassés : une malédiction qui touche également les sites d’information scientifique
La relative éphemérité des contenus du web se pose également dans le domaine de l’information scientifique et technique. On sait qu’il existe un risque important de déperdition des publications scientifiques, notamment du côté des revues en open access comme en témoigne un article d’août 2020 opportunément intitulé Open is not Forever.
En 2015, un article du New Yorker dressait un tableau de la situation. A l’époque, le site InternetActu s’en était fait l’écho :
Comme nous l’explique le New Yorker, une étude parue en 2014 et commanditée par l’école de droit de Harvard montre que 70 % des références données par la Harvard Law Review et d’autres journaux de droit, et 50 % des URLs pointant sur les opinions de la Cour Suprême ne fournissent pas les liens corrects vers l’information originale citée. » Par ailleurs, continue le New Yorker, une équipe de l’institut de Los Alamos a étudié plus de trois millions d’articles universitaires parus dans les domaines scientifiques médicaux et technologiques entre 1997 et 2002. Un lien sur cinq était mort.
Perma.cc : une solution pour nantis
L’étude commanditée par l’Ecole de Droit de Harvard dont il est question plus haut ne se contente pas de tirer le bilan préoccupant de l’obsolescence des liens dans les textes juridiques, elle présente sous la forme d’un service web intitulé perma.cc une solution destinée à limiter cette perte d’information. Ce site permet en effet de créer des permaliens et de conserver avec un compte individuel la capture des articles qui nous intéressent. Ces captures peuvent être rendues accessibles à tout le monde quand la publication est ouverte ou bien seront restreintes aux membres de la communauté qui a souscrit un abonnement à cette ressource si son accès est payant.
Bien qu’il soit normalement accessible aux seuls abonné.e.s, l’article du New-Yorker qui est également plus haut, se trouve justement accessible à tout.e.s sous la forme d’une capture d’écran depuis le site de Perma.cc.
Les créateurs de Perma.cc vendent des abonnements aux bibliothèques (particulièrement aux bibliothèques juridiques) qui permettent à leurs abonnés de conserver ainsi sous la forme de liens pérennes l’intégrité des citations qu’ils insèrent dans leurs publications.
C’est précisément là que le bât blesse : je ne vois pas beaucoup de bibliothèques qui accepteraient de payer pour que leurs abonnés puissent rédiger des bibliographiques utilisables sur le long terme. A chaque besoin documentaire dans le domaine juridique correspond en général un produit coûteux et réservé aux happy few, quand dans les autres disciplines on apprend à faire avec ce que le web met à notre disposition. Internet Archive existe, pourquoi ne pas s’en servir pour réaliser des webographies durables ?
Fatcat : l’initiative d’Internet Archive pour sauvegarder les articles en open access
Depuis 2017, Internet Archive fait grandir son archive Fatcat destinée à archiver une part importante des publications scientifiques en open access (articles, mais aussi prépublications, actes de conférence, et tout le champ de la littérature grise). Cette collecte est très largement opérée par des bots. Les utilisateurs en se créant un compte peuvent compléter les métadonnées qui accompagnent les documents. Celles-ci proviennent de datacite, crossref, Unpaywall ou encore Pubmed. Fatcat récupère également sur le web des PDF dépourvus de métadonnées et grâce à l’extracteur Grobid (de mémoire le même qui fonctionne sur HAL) extrait le plus grand nombre de métadonnées possibles du fichier. Ce sont surtout ces dernières qui auraient besoin d’être complétées par des humains. Un chercheur peut donc espérer trouver l’article qu’il cherche dans ce catalogue d’archives en interrogeant le moteur de recherche associé à Fatcat. Pour en savoir plus sur Fatcat, je recommande la lecture du billet d’Aaron Tay consacré à cette initiative.

texte de 1894 conservé dans les Keepers Registry et accessible depuis Fatcat. Le texte est par ailleurs disponible dans le corpus Istex auquel ont accès toutes les personnes relevant de l’enseignement supérieur en France
Memento : ou comment archiver l’information scientifique depuis Zotero
A côté des moyens développés pour mettre en place Fatcat, ce qui suit relève plutôt de l’artisanat, mais un artisanat où le chercheur a une part dans la collecte mondiale à travers un outil qu’il utilise quotidiennement, son gestionnaire de références.
Permettre à chacun d’archiver durablement les références qui soutiennent son travail, c’est vraisemblablement le but que s’est fixé le concepteur de Memento, un plugin pour Zotero, le gestionnaire de références bibliographiques qu’on ne présente plus.
Memento ne se charge pas exactement comme les autres plugins pour Zotero. Il faut suivre les instructions d’installation à la lettre, et notamment archiver le contenu en .zip et non pas en .7z (pour ceux qui ont l’habitude d’utiliser ce service pour compresser des fichiers). La conversion du .zip en .xpi fonctionne, ce qui n’est pas le cas pour la conversion depuis .7z. Puis dans le gestionnaire des extensions de Zotero (comme d’habitude cette fois), il convient de sélectionner l’option installer depuis un fichier et sélectionner le fichier .xpi obtenu à partir de l’archive de ces fichiers. Il ne reste plus alors qu’à redémarrer Zotero pour rendre actif le plugin.
A partir du moment où le plugin est activé, chaque référence ajoutée à une collection se voit attribuer automatiquement un lien vers sa copie sauvegardée sur Internet Archive. Ce lien est pérenne et ne peut donc être cassé en cas de changement opéré sur le site du fournisseur. Ne pas en déduire, s’il s’agit d’un article à péage, que la version sauvegardée de l’article sera la version complète à laquelle on a soi-même accès en tant qu’abonné : Internet Archive n’est pas un site destiné à contourner les verrous numériques. Toutefois le résumé de l’article au moins continuera d’être accessible et le lien dans la citation ne mènera jamais à une erreur 404.
Dans les métadonnées de la référence, le champ extra reçoit l’URL de la page correspondant à l’article sur Internet Archive. Si le champ comporte déjà des informations (ajoutées à la main ou provenant d’un autre plugin), le lien vers l’archive s’ajoute simplement au texte déjà présent.
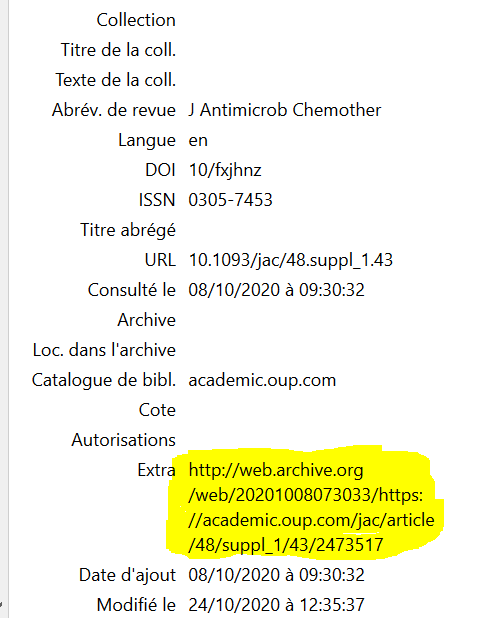
Il est donc théoriquement possible, comme le recommande le Bluebook, le référentiel de citations juridiques américains, d’associer à ses références bibliographiques systématiquement deux liens : celui qui mène vers le site du fournisseur et celui qui mène vers la page d’Internet Archive où l’article (ou son résumé) a été conservé.
Memento : un plugin lui-même menacé d’obsolescence
Toutefois, à l’usage deux obstacles viennent entraver ce fonctionnement.
Le premier est je l’espère temporaire : jusqu’à une date récente (mi-septembre ?), le plugin fonctionnait très bien lors de l’import de la référence ou bien lorsque par un clic droit sur la référence déjà présente dans la collection on cherchait à archiver une copie de l’article dans Internet Archive ou Archive.is. Ce n’est plus le cas aujourd’hui semble t-il. L’envoi vers ces serveurs est bloqué sans qu’il soit toujours possible d’obtenir un message d’erreur. J’espère qu’il ne s’agit que d’un bug qui pourra être résolu rapidement.
Le second me semble plus sérieux : comment obtenir l’inscription de ce deuxième lien dans la bibliographie ? Le style bibliographique choisi devrait être conçu de telle sorte que le champ extra s’affiche. En CSL, la grammaire dans laquelle les styles bibliographiques sont rédigés, le champ note est l’équivalent du champ extra. Certains styles affichent par défaut ce champ, c’est le cas par exemple du style “APA annotated bibliography”. Tous les autres styles peuvent être modifiés de sorte qu’ils permettent à l’instar de ces styles adaptés aux bibliographies annotées l’inscription du contenu du champ extra dans la note précédé du préfixe souhaité, mettons lien pérenne: . Avec un peu de pratique des styles, un outil comme CSL visual editor permet de modifier son style de référence de sorte qu’il intègre l’affichage des notes.
Toutefois, même avec un style correctement modifié en ce sens ou acceptant nativement les notes, le lien vers internet archive ne s’affiche que s’il est précédé d’un caractère ou d’une espace, ce qui n’est pas le cas par défaut. J’ai signalé ce problème sur le forum Zotero. La demande a suscité très rapidement une réaction de la part des développeurs de Zotero, mais à ce jour aucune solution n’a encore été trouvée.
Je regrette de n’avoir par les compétences nécessaires pour contribuer à la restauration de ce plugin, et j’espère que d’autres utilisateurs à la fois convaincus par l’importance de conserver des liens pérennes dans des travaux universitaires et capables d’améliorer le code de cette extension pourront remettre les choses d’aplomb. Internet Archive est un outil formidable contre l’érosion des connaissances, nous ne devrions pas avoir à dépendre de services payants comme Perma.cc pour faire de nos notes de bas de page des ponts et non des cul-de-sacs.